Analysis of Heavy Metal Lyrics - Part 5: Multi-label genre classification with bag-of-words models
This article is a part of my heavy metal lyrics project. Below is a lyrics-based genre classifier demonstrating a few different machine learning models (click here for full-size version). If you’re interested in seeing the full code (a lot is omitted here), check out the original notebook.
Note: Dashboard may take a minute to load
Summary
The aim of this post is to demonstrate a machine learning approach to tagging heavy metal songs with genre labels based on their lyrics alone. The task is to develop a model which will predict for a given piece of text which genre(s) describe the text well.
This notebook will implement and discuss the usage of:
- Binary relevance as a multi-label classification framework
- Multi-label classification cross-validation and evaluation metrics
- Bag-of-words text representation (and why it is favorable over word embeddings for this task!)
- Oversampling methods to curb the effects of imbalanced datasets
- A wide range of different classification models including:
- Logistic regression
- Bayesian methods
- Ensemble/boosting methods
- Neural networks
Table of contents
Imports
Show code
import glob
import os
import re
from copy import deepcopy
import numpy as np
import pandas as pd
import scipy
from scipy.sparse.csr import csr_matrix
from scipy.sparse.lil import lil_matrix
import itertools
import matplotlib.pyplot as plt
plt.style.use('seaborn')
import seaborn as sns
sns.set(font_scale=2)
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_selection import SelectKBest
from sklearn.model_selection import train_test_split, StratifiedKFold, KFold
from sklearn.metrics import balanced_accuracy_score, precision_score, recall_score, f1_score, \
confusion_matrix, multilabel_confusion_matrix, roc_curve, roc_auc_score, precision_recall_curve
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.naive_bayes import MultinomialNB, ComplementNB, BernoulliNB
from skmultilearn.model_selection import IterativeStratification
from skmultilearn.problem_transform import BinaryRelevance, ClassifierChain, LabelPowerset
from keras.models import Sequential
from keras import layers
from keras.wrappers.scikit_learn import KerasClassifier
from tensorflow.keras.callbacks import EarlyStopping
import lightgbm as lgb
import sys
sys.path.append('../scripts/')
from nlp import tokenize
from mlsol import MLSOL
import lyrics_utils as utilsFix random seeds
Show code
import random
import tensorflow.python.keras.backend as K
sess = K.get_session()
seed = 0
os.environ['PYTHONHASHSEED']=str(seed)
random.seed(seed)
np.random.seed(seed)
tf.set_random_seed(seed)
session_conf = tf.compat.v1.ConfigProto(intra_op_parallelism_threads=1, inter_op_parallelism_threads=1)
sess = tf.compat.v1.Session(graph=tf.compat.v1.get_default_graph(), config=session_conf)
tf.compat.v1.keras.backend.set_session(sess)Data
See the previous chapters for more discussion about the data set. The data set is formatted as an array comprised of one independent variable (lyrics, retrieved from Dark Lyrics) and five dependent variable labels (genres, retrieved from Metal-Archives), for each row (song). Here are some things to keep in mind about the data:
- Each song can belong to any one or more, or none, of the genres. For example, a song can be labeled as thrash metal, or both thrash and power metal, and so on, or it can be unlabeled; it can therefore be predicted to be any combination of labels, or unlabeled, as well. This makes the task of tagging song lyrics with the appropriate genre labels a multi-label classification problem.
- The dataset is multi-lingual, since heavy metal spans many languages around the world. This will affect classification since there are correlations between genres and country of origin, as show in the previous chapter. Some filtering of non-English lyrics was done in the pre-processing, but it’s not perfect.
- The length of song lyrics can vary wildly, but this won’t be a big issue in a bag-of-words representation.
Show code
df = pd.read_csv('../songs-ml-10pct.csv')
X = df.pop('lyrics').values
y = df.values
genres = df.columns
print(f"number of songs: {X.shape[0]}")
print(f"number of labels: {y.shape[1]}")
print(f"labels: {list(genres)}")number of songs: 109633 number of labels: 5 labels: ['black', 'death', 'heavy', 'power', 'thrash']
Multi-label classification methods
Binary relevance is the simplest method of classifying multiple labels at once; it trains an independent classifier for each label, breaking the multi-label problem down into many binary classification problems (Zhang, M., Li, Y., Liu, X., et al, 2018). In this context a binary classifier would be trained on each genre, and a song’s genre tags predicted by concatenating the predictions of all genre classifiers. The advantage of this method is that the number of classifiers needed is equal to the number of labels, so the computational cost scales linearly with how many labels we want to predict. However, by assuming that the labels are independent, this method fails to capture correlations between labels. For example, the “heavy” and “power” genre labels are more likely to appear together, so a song’s likelihood of being tagged as power metal should be higher if it is also tagged as heavy metal as opposed to, say, black metal. Another issue is that each binary classifier will face a class imbalance problem due to the sparsity of genre tags.
In the classifier chain method, a classifier is trained on one label and its output is fed as an additional feature to the next label, and so on until all labels have been exhausted (Read, J., Pfahringer, B., Holmes., G, Frank, E. 2011). This again requires only as many classifiers as there are labels, but unlike binary relevance it does learn correlations between labels. However, the correlations it is capable of learning can vary with different chain orders.
Unlike the above two methods, which transform the multi-label problem into multiple independent binary classification problems, the label powerset method transforms it into a single multi-class problem by treating every combination of labels as its own class. For example, from the genres in the metal lyrics dataset, “black” + “death”, “black” + “power”, “black” + “death” + “power” would each yield a new class. This tackles the issue of correlated labels head-on by treating correlations as classes on their own, but comes at the cost of having smaller class sizes to train on and consequently an even bigger class imbalance problem. This issue inspired the RAndom k-labELsets (RAKEL) method, which uses an ensemble of classifiers, each trained on a random subset of labels (Rokach, L., Schclar, A., Itach, E. 2013).
For this analysis I’ll simply use binary relevance, as implemented by the scikit-multilearn library.
Evaluation metrics
Since binary relevance involves training independent binary classifiers, each classifier can be evaluated during training and cross-validation using the familiar binary classification metrics.
However, evaluating the overall results requires metrics designed for the multi-label output, which are more complicated than the usual evaluation metrics (Zhang, M., Zhou, Z. 2014). If \(h(\mathbf{x}_i)\) is the model which predicts the labels \(Y_i\) based on the independent variables \(\mathbf{x}_i\), then over \(p\) observations the accuracy, precision, recall, and F scores are defined as
\[\begin{align} \mathrm{accuracy}(h) &= \frac{1}{p}\sum_{i=1}^{p}(\mathrm{fraction\ of\ labels\ in\ common}) &= \frac{1}{p}\sum_{i=1}^{p}\frac{|Y_i \cap h(\mathbf{x}_i)|}{|Y_i \cup h(\mathbf{x}_i)|}\\ \mathrm{precision}(h) &= \frac{1}{p}\sum_{i=1}^{p}(\mathrm{fraction\ of\ predicted\ labels\ that\ are\ correct}) &= \frac{1}{p}\sum_{i=1}^{p}\frac{|Y_i \cap h(\mathbf{x}_i)|}{|h(\mathbf{x}_i)|}\\ \mathrm{recall}(h) &= \frac{1}{p}\sum_{i=1}^{p}(\mathrm{fraction\ of\ true\ labels\ that\ were\ predicted\ correctly}) &= \frac{1}{p}\sum_{i=1}^{p}\frac{|Y_i \cap h(\mathbf{x}_i)|}{|Y_i|}\\ \mathrm{F_1\ score}(h) &= \mathrm{harmonic\ mean\ of\ precision\ and\ recall} &= 2 \left[ \frac{\mathrm{precision}(h) \cdot \mathrm{recall}(h)}{\mathrm{precision}(h) + \mathrm{recall}(h)} \right] \end{align}\]Another useful metric is the Hamming loss, which is the mean symmetric difference (non-matching genre tags) between the two sets:
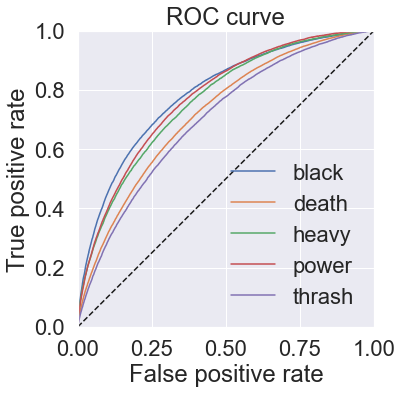
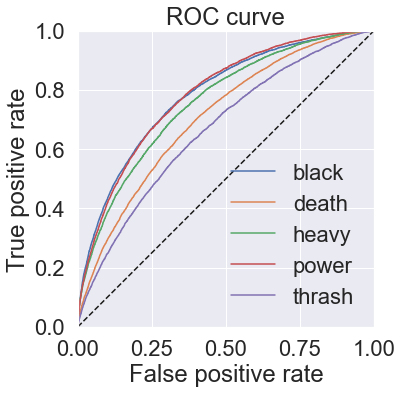
\[\mathrm{Hamming}(h) = \frac{1}{p} \sum_{i=1}^{p} |h(\mathbf{x}_i\Delta Y_i|\]The receiver operating characteristic (ROC) is a common metric for binary classification problems that can be easily extended to multi-label problems. ROC measures the ratio of true positive rate to false positive rate as a function of classification threshold. An ROC curve is generated by varying the threshold over its full range, and the area under the curve (ROC AUC) is often used as another evaluation metric. This can be micro- or macro-averaged across all binary classifiers to evaluate the full multi-label classification model.
To handle all of these metrics for multi-label results, I define an object for collecting results after model training that can save or report metrics:
Show code
class MultiLabelClassification:
"""Multi-label classification results and evaluation metrics.
Parameters
----------
true : `numpy.ndarray`
True values (n_samples, n_labels).
pred : `numpy.ndarray`
Predicted probabilities (n_samples, n_labels).
pred_class : `numpy.ndarray`
Classification results (n_samples, n_labels).
labels : array-like
Label names (str).
threshold : float or array-like
If float, `thresh` is a decision threshold for all labels.
If array-like, `thresh` must be length n_labels, with each
value a decision threshold for that respective label.
Attributes
----------
n_samples : int
Number of samples (rows in `self.true`).
n_labels : int
Number of labels (columns in `self.true`).
accuracy_score : float
Number of labels in common / overall labels (true and predicted).
precision_score : float
Proportion of predicted labels that are correct.
recall_score : float
Proportion of true labels that were predicted.
f1_score : float
Harmonic mean of precision_score and recall_score.
hamming_loss : float
Symmetric difference b/w pred and true labels (true XOR pred).
Methods
-------
print_report
best_thresholds
roc_auc_score
plot_roc_curve
plot_precision_recall_curve
to_csv
from_csv
"""
def __init__(
self,
true,
pred=None,
pred_class=None,
labels=None,
threshold=0.5
):
self.true = true.astype(int)
self.pred = pred
self.threshold = threshold
if pred_class is None:
pred_class = np.zeros_like(self.pred, dtype=int)
if hasattr(self.threshold, '__iter__'):
thresh_tile = np.ones_like(self.true) * self.threshold
else:
thresh_tile = np.tile(self.threshold, (self.true.shape[0], 1))
pred_class[self.pred > thresh_tile] = 1
self.pred_class = pred_class
self.n_samples, self.n_labels = self.true.shape
if labels is not None:
if len(labels) == self.n_labels:
self.labels = np.array(labels, dtype='object')
else:
raise ValueError(
f"len(labels)={len(labels)} does not match "
f"true.shape[1]={self.n_labels}")
else:
self.labels = np.arange(self.true.shape[1]).astype(str).astype('object')
@property
def __intersection(self):
return self.true * self.pred_class
@property
def __union(self):
return np.minimum(1, self.true + self.pred_class)
@property
def accuracy_score(self):
return np.nanmean(self.__intersection.sum(1) / self.__union.sum(1))
@property
def precision_score(self):
return np.nanmean(self.__intersection.sum(1) / self.pred_class.sum(1))
@property
def recall_score(self):
return np.nanmean(self.__intersection.sum(1) / self.true.sum(1))
@property
def f1_score(self):
prec = self.precision_score
rec = self.recall_score
return 2 * prec * rec / (prec + rec)
@property
def hamming_loss(self):
delta = np.zeros(self.true.shape[0])
for i in range(delta.shape[0]):
delta[i] = np.sum(self.true[i] ^ self.pred_class[i])
return delta.mean()
@property
def roc_auc_score(self):
"""Area under receiver operating characteristic (ROC) curve.
"""
auc = np.zeros(len(self.labels))
for i, label in enumerate(self.labels):
auc[i] = roc_auc_score(self.true[:, i], self.pred[:, i])
return auc
def print_report(self, full=False):
"""Print results of classification.
"""
np.seterr(divide='ignore', invalid='ignore')
if full:
print("\nBinary classification metrics:")
metrics = [
'balanced_accuracy_score', 'precision_score',
'recall_score', 'f1_score']
exec(f"from sklearn.metrics import {', '.join(metrics)}")
scores = {metric: np.zeros(self.n_labels) for metric in metrics}
for i, label in enumerate(self.labels):
if full:
print(f"\nlabel: {label}")
true_i = self.true[:, i]
pred_i = self.pred_class[:, i]
for metric in metrics:
score = eval(f"{metric}(true_i, pred_i)")
scores[metric][i] = score
if full:
print(f" {metric.replace('_score', '')[:19]:<20s}"
f"{score:.3f}")
cfm = confusion_matrix(true_i, pred_i)
if full:
print(" confusion matrix:")
print(f" [[{cfm[0, 0]:6.0f} {cfm[0, 1]:6.0f}]\n"
f" [{cfm[1, 0]:6.0f} {cfm[1, 1]:6.0f}]]")
print(f"\nAverage binary classification scores:")
for metric in metrics:
avg = scores[metric].mean()
std = scores[metric].std()
print(f" {metric.replace('_score', '')[:19]:<20s}"
f"{avg:.2f} +/- {std * 2:.2f}")
print("\nMulti-label classification metrics:")
print(f" accuracy {self.accuracy_score:.2f}")
print(f" precision {self.precision_score:.2f}")
print(f" recall {self.recall_score:.2f}")
print(f" f1 {self.f1_score:.2f}")
print(f" hamming loss {self.hamming_loss:.2f}")
auc_scores = self.roc_auc_score
print(f"\nROC AUC scores:")
for label, auc_score in zip(self.labels, auc_scores):
print(f" {label:<10s}: {auc_score:.3f}")
print(f" macro-avg : {np.mean(auc_scores):.3f} "
f"+/- {np.std(auc_scores):.3f}")
return
def best_thresholds(self, metric='gmean', fbeta=1):
"""Determine best thresholds by maximizing geometric mean
or f_beta score.
"""
best = np.zeros(len(self.labels))
for i, label in enumerate(self.labels):
true, pred = self.true[:, i], self.pred[:, i]
if metric == 'gmean':
fpr, tpr, thresholds = roc_curve(true, pred)
gmean = np.sqrt(tpr * (1 - fpr))
best[i] = thresholds[gmean.argmax()]
elif metric == 'fscore':
prec, rec, thresholds = precision_recall_curve(true, pred)
fscore = ((1 + fbeta**2) * prec * rec) / ((fbeta**2 * prec) + rec)
best[i] = thresholds[fscore.argmax()]
return best
def plot_roc_curve(self):
"""Plot receiver-operating characteristic (ROC) curve.
"""
fig, ax = plt.subplots(1, 1, figsize=(8, 6))
for i, label in enumerate(self.labels):
true = self.true[:, i]
pred = self.pred[:, i]
fpr, tpr, thresholds = roc_curve(true, pred)
ax.step(fpr, tpr, label=label)
ax.plot([0, 1], [0, 1], 'k--')
ax.set_aspect('equal')
ax.set_xlim([0, 1])
ax.set_ylim([0, 1])
ax.set_title("ROC curve")
ax.set_xlabel("False positive rate")
ax.set_ylabel("True positive rate")
ax.legend()
ax.grid(True)
fig.tight_layout()
return fig
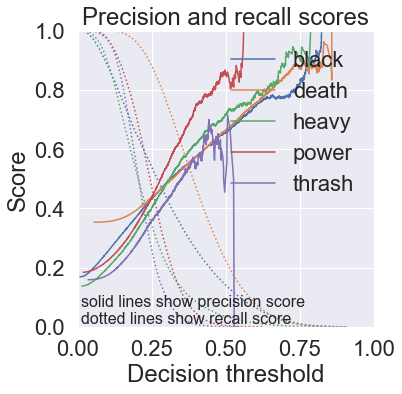
def plot_precision_recall_curve(self):
"""Plot precision and recall against decision threshold.
"""
fig, ax = plt.subplots(1, 1, figsize=(8, 6))
for i, label in enumerate(self.labels):
true, pred = self.true[:, i], self.pred[:, i]
prec, rec, thresholds = precision_recall_curve(true, pred)
line = ax.plot(thresholds, prec[:-1], label=label)
ax.plot(thresholds, rec[:-1], ":", color=line[0].get_color())
ax.set_aspect('equal')
ax.set_xlim([0, 1])
ax.set_ylim([0, 1])
ax.set_title("Precision and recall scores")
ax.set_xlabel("Decision threshold")
ax.set_ylabel("Score")
ax.text(0.01, 0.01, "solid lines show precision score\n"
"dotted lines show recall score", size=16)
ax.legend(loc='upper right')
ax.grid(True)
fig.tight_layout()
return fig
def to_csv(self, filename):
"""Save true labels, probabilities, and predictions to CSV.
"""
data = {}
for i, label in enumerate(self.labels):
data[f"{label}_true"] = self.true[:, i]
data[f"{label}_pred"] = self.pred[:, i]
data[f"{label}_pred_class"] = self.pred_class[:, i]
df = pd.DataFrame.from_dict(data)
df.to_csv(filename, index=False)
return
@classmethod
def from_csv(cls, filename):
"""Load classification from CSV.
"""
data = pd.read_csv(filename)
cols = data.columns
true = data[[c for c in cols if c[-4:] == 'true']].values
pred = data[[c for c in cols if c[-4:] == 'pred']].values
labels = [c.replace('_true', '') for c in cols if c[-4:] == 'true']
pred_class = data[[c for c in cols if c[-10:] == 'pred_class']].values
new = cls(true, pred, pred_class=pred_class, labels=labels)
return newPipeline
Two pre-processing steps must be performed before a model can be trained on this dataset:
-
Vectorization: To transform the data from raw song lyrics to an array of values ready for training, the lyrics must be vectorized. In this notebook this will be done using a bag-of-words representation, which simply transforms the corpus into a matrix whose rows represent documents (songs) and columns represent words. The value of each word in a document is determined by the vectorization method. The
CountVectorizerwill populate this matrix with raw word counts; theTfidfVectorizertakes this an extra step by computing the term-frequency inverse-document-frequency (TF-IDF) value for each term in a document. TF-IDF measures the frequency of a term in a document relative to its frequency in all documents, thus providing a better measure of how unique the term is to that document.A shortcoming of the bag-of-words representation is that it fails to capture any syntactical structure in the lyrics. A popular alternative is to implement a word embedding, which generates a vector space representation of all the words in the data set, Since this method allows a document to be transformed into series of word-vectors, it opens up the possibility of training models that is sensitive to the word ordering. That said, in the case of song lyrics, syntax is usually unimportant, if it even exists. Lyrics are often comprised of broken phrases that combine words in unusual ways and may not necessarily convey meaning in the way that prose sentences do. Punctuation is scarce, its usage often a stylistic decision of the transcriber. For these reasons, a bag-of-words representation should suffice, and may even outperform word embeddings.
-
Oversampling: To remedy the class imbalance in each single-genre binary classification, the data can be either oversampled or undersampled to have an equal number of positive and negative class occurrences. Undersampling requires no manipulation of the data; the classifier is simply trained with a subset of the majority class equal in number to the minority class. This comes at the cost of reducing the amount of data to train from, so oversampling is often preferred over undersampling. The simplest method of oversampling is random oversampling, in which randomly selected rows from the minority class are duplicated during training. Synthetic Minority Oversampling Technique (SMOTE) is a more complex method that generates new data based on the distribution of values in the minority class Chawla, N., Bowyer, K., Hall, L., Kegelmeyer, W. 2011. It does so by randomly selecting two observations at a time in the minority class and sampling a new observation from the line between those two in the feature space. This is somewhat like producing from randomly selected parent observations a child whose traits are somewhere between those of its parents. In the context of song lyrics SMOTE would generate new songs with word frequencies (or TF-IDF values) similar to the genre being classified by the binary classifier. In this analysis I use a multi-label version of SMOTE, called MLSOL.
Show code
class NLPipeline:
"""Pipeline for NLP classification with vectorization and resampling
Parameters
----------
vectorizer : transformer object
Object with `fit_transform` and `transform` methods for vectorizing
corpus data.
resampler : resampler object
Object with fit_resample method for resampling training data in
`Pipeline.fit`. This can be any under/oversampler from `imblearn`
for binary or multiclass classification, or `MLSOL` from
https://github.com/diliadis/mlsol/blob/master/MLSOL.py for multi-label
classification.
classifier : estimator object
Binary, multi-class, or multi-label classifier with a `predict`
or `predict_proba` method.
Methods
-------
fit(X, y)
Fit vectorizer and resampler, then train classifier on transformed data.
predict(X)
Return classification probabilities (if `self.classifier` has a
`predict_proba` method, otherwise return predictions using `predict`).
"""
def __init__(self, vectorizer, resampler, classifier, pad_features=False):
self.vectorizer = vectorizer
self.resampler = resampler
self.classifier = classifier
self.pad_features = pad_features
self.padding = 0
self.threshold = None
self.labels = None
@property
def features(self):
feature_names = self.vectorizer.get_feature_names_out()
if self.pad_features:
feature_names + [''] * self.padding
return
def apply_padding(self, X):
if self.padding > 0:
padding_array = np.zeros((X.shape[0], self.padding))
X = np.concatenate((X, padding_array), axis=1)
return X
def fit(self, X, y, labels=None, **kwargs):
self.labels = labels
X_v = self.vectorizer.fit_transform(X).toarray()
if self.pad_features:
self.padding = self.vectorizer.max_features - len(self.vectorizer.get_feature_names())
X_v = self.apply_padding(X_v)
X_r, y_r = self.resampler.fit_resample(X_v, y)
self.classifier.fit(X_r, y_r, **kwargs)
return self
def predict(self, X):
X_v = self.vectorizer.transform(X).toarray()
X_v = self.apply_padding(X_v)
try:
y_p = self.classifier.predict_proba(X_v)
except AttributeError:
y_p = self.classifier.predict(X_v)
if (
isinstance(y_p, csr_matrix) or
isinstance(y_p, lil_matrix)
):
y_p = y_p.toarray()
return y_p
def set_threshold(self, threshold):
self.threshold = threshold
return
def classify_text(self, text):
X_test = np.array([' '.join(text.lower().split())])
prob = self.predict(X_test)[0]
if self.threshold is not None:
pred = prob > self.threshold
else:
pred = prob > 0.5
if self.labels is not None:
labels = self.labels
else:
labels = range(len(pred))
results = [(label, prob[i], pred[i]) for i, label in enumerate(labels)]
results.sort(key=lambda x: 1 - x[1])
print("Classification:")
if results[0][2] < 1:
print("NONE")
else:
print(", ".join([res[0].upper() for res in results if res[2] > 0]))
print("\nIndividual label probabilities:")
for res in results:
print("{:<10s}{:>3.0f}%".format(res[0], 100 * res[1]))
returnCross-validation
Cross-validation can be used to evaluate the performance of the machine learning pipeline.
In cross-validation, the training data are split into n_splits subsets,
and the model is trained on all but one subset, with the last used as a “validation set”.
We can repeat this with each subset taking its turn as the validation set,
and average the evaluation metrics from all runs.
Show code
def multilabel_pipeline_cross_val(pipeline, X, y, labels=None, n_splits=3, verbose=0, keras=False, callbacks=None):
"""Multi-label pipeline cross-validation
Parameters
----------
pipeline : `sklearn.pipeline.Pipeline` or custom pipeline
Must have .fit and .predict methods
X : array-like
y : array-like
(n_samples x n_labels)
labels : array-like
Label names (numerical if Default = None)
n_splits : int
Number of cross-validation splits (Default = 3)
Returns
-------
mlc : `multilabel.MultiLabelClassification`
Multi-label classification results
folds : list
(train_idx, valid_idx) pair for each CV fold
"""
kfold = IterativeStratification(n_splits=n_splits, order=1, random_state=None)
pred = np.zeros_like(y, dtype=float)
thresh_folds = np.zeros((y.shape[1], n_splits))
for i, (train_idx, valid_idx) in enumerate(kfold.split(X, y)):
if verbose > 0:
print(f"\n--------\nFold {i+1}/{kfold.n_splits}")
X_train, y_train = X[train_idx], y[train_idx]
X_valid, y_valid = X[valid_idx], y[valid_idx]
if keras:
pipeline.fit(X_train, y_train, labels=labels, validation_split=0.2, callbacks=callbacks)
else:
pipeline.fit(X_train, y_train, labels=labels)
valid_pred = pipeline.predict(X_valid)
pred[valid_idx] = valid_pred
mlc_valid = MultiLabelClassification(y_valid, valid_pred, labels=labels)
thresh_folds[:, i] = mlc_valid.best_thresholds('gmean')
if verbose > 0:
mlc_valid.print_report(full=(verbose > 1))
threshold = thresh_folds.mean(axis=1)
mlc = MultiLabelClassification(
y, pred=pred, labels=labels, threshold=threshold)
if verbose > 0:
print("\n------------------------\nCross-validation results")
mlc.print_report(full=True)#(verbose > 1))
return mlctest_corpus = ['', 'satan', 'flesh', 'fight', 'attack']Vectorizer
Show code
def tokenizer(s):
tokens = tokenize(s.strip(), english_only=True)
tokens = [t for t in tokens if len(t) >= 4]
return tokensvectorizer = TfidfVectorizer(
stop_words=stopwords.words('english'),
tokenizer=tokenizer,
min_df=0.01,
max_df=0.9,
max_features=1000,
sublinear_tf=False,
)Logistic regression
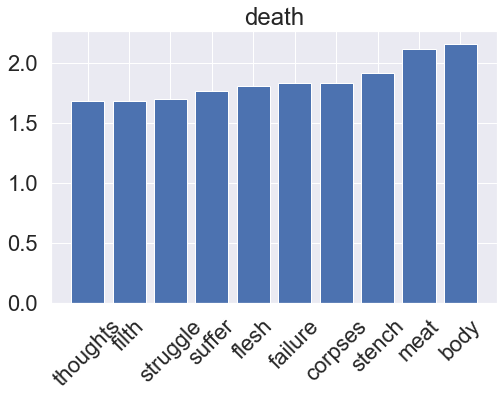
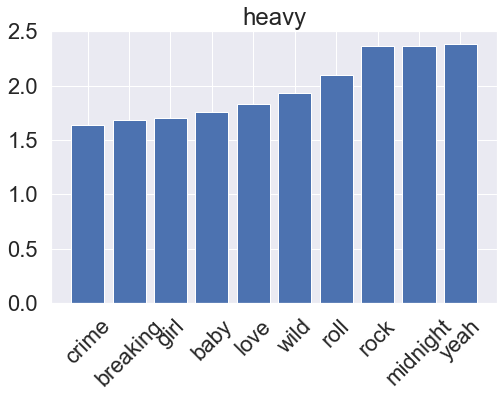
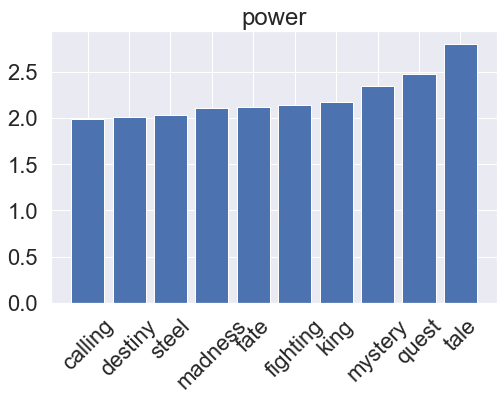
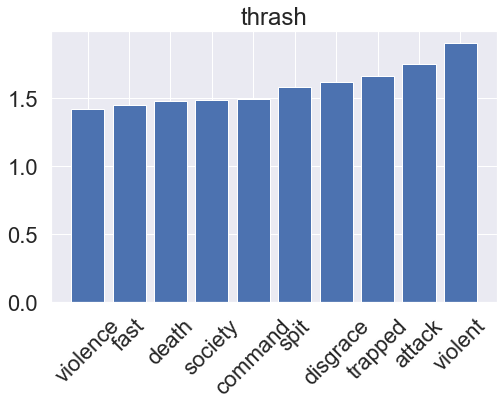
One very simple model for a binary classification task is the LogisticRegression classifier, which assumes a linear relationship between the feature variables (word counts) and the log-odds of the target variables (genre). Logistic regression is a very common tool for tackling classification problems in a variety of applications, sometimes under the names logit regression or maximum-entropy (MaxEnt) classification. After training, we can also visualize what the model has learned by accessing its feature importances. This is applicable to other models later on as well.
Pipeline
Show code
lr_params = dict(
solver='liblinear',
C=5.0,
max_iter=1000,
random_state=0
)
lr_pipeline = NLPipeline(
vectorizer=vectorizer,
resampler=MLSOL(perc_gen_instances=0.3, k=5, random_state=0),
classifier=BinaryRelevance(
LogisticRegression(**lr_params),
require_dense=[False, True]
)
)
lr_mlc = multilabel_pipeline_cross_val(lr_pipeline, X, y, labels=genres, verbose=2)
lr_mlc.plot_roc_curve()
plt.show()
lr_mlc.plot_precision_recall_curve()
plt.show()Show output
-------- Fold 1/3 1%|▉ | 280/21926 [00:03<04:30, 79.97it/s]E:\Projects\metallyrics\analyses\lyrics\notebooks\../scripts\mlsol.py:115: RuntimeWarning: invalid value encountered in double_scalars cd = dist_seed / (dist_seed - dist_reference) 100%|████████████████████████████████████████████████████████████████████████████| 21926/21926 [04:33<00:00, 80.08it/s] Binary classification metrics: label: black balanced_accuracy 0.618 precision 0.606 recall 0.272 f1 0.376 confusion matrix: [[ 29280 1092] [ 4492 1681]] label: death balanced_accuracy 0.625 precision 0.608 recall 0.385 f1 0.471 confusion matrix: [[ 20439 3204] [ 7939 4963]] label: heavy balanced_accuracy 0.572 precision 0.552 recall 0.165 f1 0.254 confusion matrix: [[ 30851 670] [ 4197 827]] label: power balanced_accuracy 0.617 precision 0.609 recall 0.274 f1 0.378 confusion matrix: [[ 28668 1180] [ 4859 1838]] label: thrash balanced_accuracy 0.522 precision 0.440 recall 0.058 f1 0.103 confusion matrix: [[ 30310 431] [ 5466 338]] Average binary classification scores: balanced_accuracy 0.59 +/- 0.08 precision 0.56 +/- 0.13 recall 0.23 +/- 0.22 f1 0.32 +/- 0.25 Multi-label classification metrics: accuracy 0.24 precision 0.60 recall 0.28 f1 0.38 hamming loss 0.92 ROC AUC scores: black : 0.803 death : 0.726 heavy : 0.770 power : 0.798 thrash : 0.691 macro-avg : 0.757 +/- 0.043 -------- Fold 2/3 100%|████████████████████████████████████████████████████████████████████████████| 21926/21926 [04:21<00:00, 83.99it/s] Binary classification metrics: label: black balanced_accuracy 0.622 precision 0.605 recall 0.281 f1 0.384 confusion matrix: [[ 29238 1133] [ 4438 1736]] label: death balanced_accuracy 0.627 precision 0.608 recall 0.391 f1 0.476 confusion matrix: [[ 20386 3257] [ 7859 5043]] label: heavy balanced_accuracy 0.573 precision 0.579 recall 0.166 f1 0.258 confusion matrix: [[ 30914 607] [ 4189 835]] label: power balanced_accuracy 0.618 precision 0.584 recall 0.280 f1 0.378 confusion matrix: [[ 28509 1338] [ 4823 1875]] label: thrash balanced_accuracy 0.523 precision 0.448 recall 0.059 f1 0.104 confusion matrix: [[ 30320 420] [ 5464 341]] Average binary classification scores: balanced_accuracy 0.59 +/- 0.08 precision 0.56 +/- 0.12 recall 0.24 +/- 0.23 f1 0.32 +/- 0.26 Multi-label classification metrics: accuracy 0.25 precision 0.60 recall 0.28 f1 0.39 hamming loss 0.92 ROC AUC scores: black : 0.799 death : 0.725 heavy : 0.775 power : 0.790 thrash : 0.692 macro-avg : 0.756 +/- 0.041 -------- Fold 3/3 100%|████████████████████████████████████████████████████████████████████████████| 21927/21927 [04:30<00:00, 81.16it/s] Binary classification metrics: label: black balanced_accuracy 0.625 precision 0.600 recall 0.290 f1 0.391 confusion matrix: [[ 29178 1191] [ 4386 1788]] label: death balanced_accuracy 0.624 precision 0.606 recall 0.385 f1 0.470 confusion matrix: [[ 20408 3233] [ 7939 4963]] label: heavy balanced_accuracy 0.570 precision 0.565 recall 0.159 f1 0.249 confusion matrix: [[ 30904 616] [ 4222 801]] label: power balanced_accuracy 0.615 precision 0.595 recall 0.273 f1 0.374 confusion matrix: [[ 28604 1242] [ 4872 1825]] label: thrash balanced_accuracy 0.522 precision 0.493 recall 0.055 f1 0.099 confusion matrix: [[ 30408 330] [ 5484 321]] Average binary classification scores: balanced_accuracy 0.59 +/- 0.08 precision 0.57 +/- 0.08 recall 0.23 +/- 0.23 f1 0.32 +/- 0.26 Multi-label classification metrics: accuracy 0.25 precision 0.60 recall 0.28 f1 0.38 hamming loss 0.92 ROC AUC scores: black : 0.800 death : 0.725 heavy : 0.776 power : 0.792 thrash : 0.697 macro-avg : 0.758 +/- 0.040 ------------------------ Cross-validation results Binary classification metrics: label: black balanced_accuracy 0.727 precision 0.353 recall 0.725 f1 0.474 confusion matrix: [[ 66476 24636] [ 5100 13421]] label: death balanced_accuracy 0.663 precision 0.514 recall 0.671 f1 0.582 confusion matrix: [[ 46424 24503] [ 12753 25953]] label: heavy balanced_accuracy 0.701 precision 0.269 recall 0.708 f1 0.390 confusion matrix: [[ 65575 28987] [ 4400 10671]] label: power balanced_accuracy 0.717 precision 0.357 recall 0.730 f1 0.479 confusion matrix: [[ 63141 26400] [ 5431 14661]] label: thrash balanced_accuracy 0.637 precision 0.247 recall 0.649 f1 0.358 confusion matrix: [[ 57685 34534] [ 6104 11310]] Average binary classification scores: balanced_accuracy 0.69 +/- 0.07 precision 0.35 +/- 0.19 recall 0.70 +/- 0.06 f1 0.46 +/- 0.16 Multi-label classification metrics: accuracy 0.34 precision 0.37 recall 0.70 f1 0.48 hamming loss 1.58 ROC AUC scores: black : 0.800 death : 0.725 heavy : 0.773 power : 0.793 thrash : 0.693 macro-avg : 0.757 +/- 0.041  
Show code
print("Thresholds:", lr_mlc.threshold)
lr_pipeline.fit(X, y, labels=genres)
lr_pipeline.set_threshold(lr_mlc.threshold)
for text in test_corpus:
print(text)
lr_pipeline.classify_text(text)
print()Show output
Thresholds: [0.16887991 0.33686272 0.14670864 0.19904234 0.16859971] 100%|████████████████████████████████████████████████████████████████████████████| 32889/32889 [10:03<00:00, 54.52it/s] Classification: NONE Individual label probabilities: death 29% thrash 23% heavy 19% black 15% power 9% satan Classification: BLACK, THRASH Individual label probabilities: black 81% thrash 38% death 23% heavy 10% power 1% flesh Classification: DEATH, BLACK Individual label probabilities: death 72% black 29% thrash 8% heavy 1% power 0% fight Classification: POWER, HEAVY, THRASH Individual label probabilities: power 38% heavy 35% thrash 32% death 10% black 6% attack Classification: THRASH, HEAVY Individual label probabilities: thrash 64% death 21% heavy 20% power 16% black 16%
Feature importances
Show code
for i, clf in enumerate(lr_pipeline.classifier.classifiers_):
fi = clf.coef_[0]
fi_top = fi.argsort()[-10:]
x_vals = range(len(fi_top))
fig = plt.figure(figsize=(8, 5))
plt.bar(x_vals, fi[fi_top])
plt.title(genres[i])
plt.xticks(x_vals, np.array(vectorizer.get_feature_names_out())[fi_top], rotation=45)
plt.show()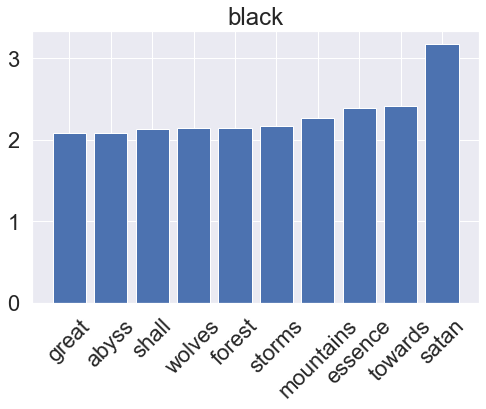
Naive Bayes
Naive Bayes classifiers have long been popular in text classification. The method is rooted in Bayes’ Theorem, which states the probability of a particular class \(y\) given input \(\mathbf{x}=(x_1, \dots, x_n)\) can be written as
\[P(y|\mathbf{x}) = \frac{P(y)P(\mathbf{x}|y)}{P(\mathbf{x})}\]where \(P(y)\), \(P(\mathbf{x}|y)\), and \(P(\mathbf{x})\) are known as the prior, likelihood and evidence. The evidence is class-independent and can be ignored when comparing the probabilities of different classes, while the likelihood can be expanded using the chain rule for probabilities as
\[\begin{align} P(\mathbf{x}|y) &= P(x_1, \dots, x_n|y)\\ &= P(x_1|x_2, \dots, x_n, y) P(x_2, \dots, x_n|y)\\ &= \dots\\ &= P(x_1|x_2, \dots, x_n, y) P(x_2| x_3 \dots, x_n, y) \dots P(x_{n-1}|x_n, y) P(x_n|y) P(y) \end{align}\]The “naive” assumption is that the input variables \(x_i\) are assumed to be mutually independent, so \(P(x_i|x_{i+1}, \dots, x_n, y) = P(x_i|y)\). Thus the likelihood becomes a product sum of single-feature probabilities \(P(x_i|y)\):
\[P(\mathbf{x}|y) = P(y) \prod_{i=1}^{n} P(x_i|y)\]Thus the Naive Bayes classification problem can be expressed as a maximum a posteriori estimation (like maximum-likelihood but with a prior term included that behaves like a regularization parameter (see this blog post for a quick discussion of MAP and MLE)) with the following classification rule:
\[\hat{y} = \mathrm{argmax}_k P(y_k) \prod_{i=1}^{n} P(x_i|y_k)\]The scikit-learn implementation NaiveBayes provides different options for the likelihood distribution \(P(x_i|y)\). The Multinomial and Bernoulli algorithms are the most popular for document classification tasks.
Multinomial Naive Bayes
Show code
multinomial_pipeline = NLPipeline(
vectorizer=vectorizer,
resampler=MLSOL(perc_gen_instances=0.3, k=5, random_state=0),
classifier=BinaryRelevance(
MultinomialNB(alpha=1.0),
require_dense=[False, True]
)
)
multinomial_mlc = multilabel_pipeline_cross_val(multinomial_pipeline, X, y, labels=genres, verbose=2)
multinomial_mlc.plot_roc_curve()
plt.show()
multinomial_mlc.plot_precision_recall_curve()
plt.show()-------- Fold 1/3 100%|████████████████████████████████████████████████████████████████████████████| 21927/21927 [04:28<00:00, 81.63it/s] Binary classification metrics: label: black balanced_accuracy 0.561 precision 0.665 recall 0.137 f1 0.227 confusion matrix: [[ 29944 425] [ 5329 845]] label: death balanced_accuracy 0.581 precision 0.664 recall 0.223 f1 0.334 confusion matrix: [[ 22183 1458] [ 10026 2876]] label: heavy balanced_accuracy 0.516 precision 0.704 recall 0.035 f1 0.067 confusion matrix: [[ 31445 74] [ 4848 176]] label: power balanced_accuracy 0.502 precision 0.960 recall 0.004 f1 0.007 confusion matrix: [[ 29845 1] [ 6673 24]] label: thrash balanced_accuracy 0.500 precision 0.333 recall 0.000 f1 0.000 confusion matrix: [[ 30736 2] [ 5804 1]] Average binary classification scores: balanced_accuracy 0.53 +/- 0.07 precision 0.67 +/- 0.40 recall 0.08 +/- 0.17 f1 0.13 +/- 0.26 Multi-label classification metrics: accuracy 0.11 precision 0.68 recall 0.12 f1 0.20 hamming loss 0.95 ROC AUC scores: black : 0.787 death : 0.723 heavy : 0.761 power : 0.774 thrash : 0.700 macro-avg : 0.749 +/- 0.033 -------- Fold 2/3 100%|████████████████████████████████████████████████████████████████████████████| 21926/21926 [04:19<00:00, 84.38it/s] Binary classification metrics: label: black balanced_accuracy 0.564 precision 0.659 recall 0.142 f1 0.234 confusion matrix: [[ 29918 453] [ 5297 877]] label: death balanced_accuracy 0.579 precision 0.659 recall 0.220 f1 0.330 confusion matrix: [[ 22176 1467] [ 10061 2841]] label: heavy balanced_accuracy 0.515 precision 0.735 recall 0.031 f1 0.060 confusion matrix: [[ 31465 57] [ 4865 158]] label: power balanced_accuracy 0.502 precision 0.825 recall 0.005 f1 0.010 confusion matrix: [[ 29841 7] [ 6664 33]] label: thrash balanced_accuracy 0.500 precision 0.667 recall 0.000 f1 0.001 confusion matrix: [[ 30740 1] [ 5802 2]] Average binary classification scores: balanced_accuracy 0.53 +/- 0.07 precision 0.71 +/- 0.13 recall 0.08 +/- 0.17 f1 0.13 +/- 0.26 Multi-label classification metrics: accuracy 0.11 precision 0.67 recall 0.11 f1 0.20 hamming loss 0.95 ROC AUC scores: black : 0.790 death : 0.722 heavy : 0.765 power : 0.773 thrash : 0.702 macro-avg : 0.750 +/- 0.033 -------- Fold 3/3 100%|████████████████████████████████████████████████████████████████████████████| 21926/21926 [04:22<00:00, 83.39it/s] Binary classification metrics: label: black balanced_accuracy 0.563 precision 0.644 recall 0.141 f1 0.232 confusion matrix: [[ 29890 482] [ 5301 872]] label: death balanced_accuracy 0.581 precision 0.667 recall 0.222 f1 0.333 confusion matrix: [[ 22211 1432] [ 10038 2864]] label: heavy balanced_accuracy 0.518 precision 0.716 recall 0.038 f1 0.071 confusion matrix: [[ 31446 75] [ 4835 189]] label: power balanced_accuracy 0.502 precision 0.800 recall 0.004 f1 0.007 confusion matrix: [[ 29841 6] [ 6674 24]] label: thrash balanced_accuracy 0.500 precision 0.667 recall 0.000 f1 0.001 confusion matrix: [[ 30739 1] [ 5803 2]] Average binary classification scores: balanced_accuracy 0.53 +/- 0.07 precision 0.70 +/- 0.11 recall 0.08 +/- 0.17 f1 0.13 +/- 0.26 Multi-label classification metrics: accuracy 0.11 precision 0.67 recall 0.12 f1 0.20 hamming loss 0.95 ROC AUC scores: black : 0.786 death : 0.721 heavy : 0.764 power : 0.778 thrash : 0.700 macro-avg : 0.750 +/- 0.033 ------------------------ Cross-validation results Binary classification metrics: label: black balanced_accuracy 0.716 precision 0.342 recall 0.709 f1 0.462 confusion matrix: [[ 65876 25236] [ 5387 13134]] label: death balanced_accuracy 0.660 precision 0.512 recall 0.667 f1 0.579 confusion matrix: [[ 46274 24653] [ 12879 25827]] label: heavy balanced_accuracy 0.689 precision 0.263 recall 0.684 f1 0.380 confusion matrix: [[ 65613 28949] [ 4759 10312]] label: power balanced_accuracy 0.704 precision 0.346 recall 0.708 f1 0.464 confusion matrix: [[ 62624 26917] [ 5874 14218]] label: thrash balanced_accuracy 0.645 precision 0.255 recall 0.644 f1 0.366 confusion matrix: [[ 59528 32691] [ 6206 11208]] Average binary classification scores: balanced_accuracy 0.68 +/- 0.05 precision 0.34 +/- 0.18 recall 0.68 +/- 0.05 f1 0.45 +/- 0.15 Multi-label classification metrics: accuracy 0.33 precision 0.36 recall 0.69 f1 0.47 hamming loss 1.58 ROC AUC scores: black : 0.788 death : 0.722 heavy : 0.763 power : 0.775 thrash : 0.701 macro-avg : 0.750 +/- 0.033
Show code
print(multinomial_mlc.threshold)
multinomial_pipeline.fit(X, y, labels=genres)
multinomial_pipeline.set_threshold(multinomial_mlc.threshold)
for text in test_corpus:
print(text)
multinomial_pipeline.classify_text(text)
print()[0.17336195 0.33192809 0.15649294 0.19828029 0.18175247] 100%|████████████████████████████████████████████████████████████████████████████| 32889/32889 [09:41<00:00, 56.52it/s] Classification: DEATH Individual label probabilities: death 34% power 19% thrash 18% black 17% heavy 16% satan Classification: BLACK, THRASH Individual label probabilities: black 52% death 33% thrash 26% heavy 12% power 9% flesh Classification: DEATH, BLACK Individual label probabilities: death 56% black 27% thrash 17% power 6% heavy 6% fight Classification: POWER, HEAVY, THRASH Individual label probabilities: power 33% heavy 24% death 22% thrash 22% black 11% attack Classification: THRASH, POWER, HEAVY Individual label probabilities: thrash 35% death 29% power 20% heavy 20% black 17%
Show code
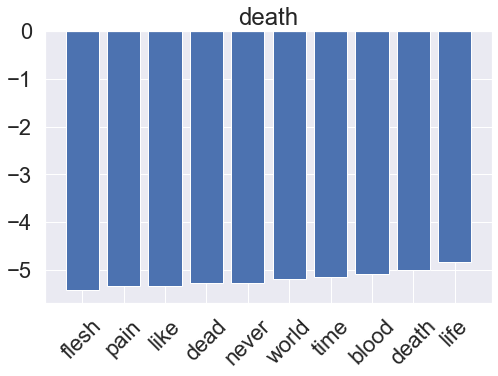
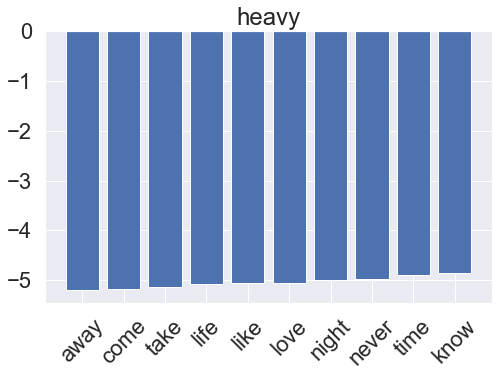
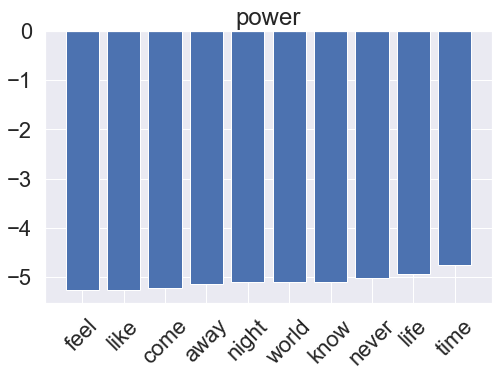
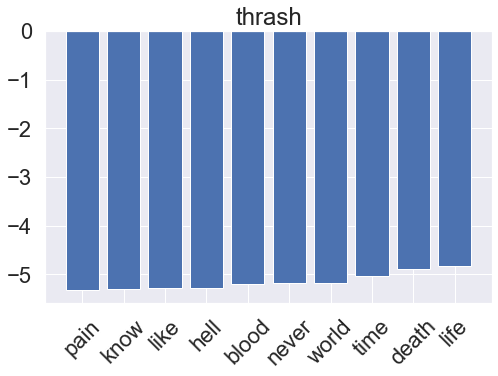
for i, clf in enumerate(multinomial_pipeline.classifier.classifiers_):
fi = clf.coef_[0]
fi_top = fi.argsort()[-10:]
x_vals = range(len(fi_top))
fig = plt.figure(figsize=(8, 5))
plt.bar(x_vals, fi[fi_top])
plt.title(genres[i])
plt.xticks(x_vals, np.array(vectorizer.get_feature_names_out())[fi_top], rotation=45)
plt.show()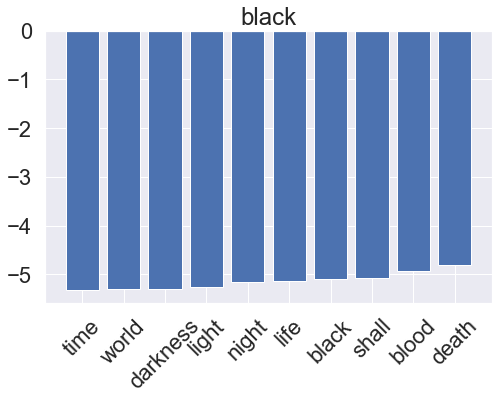
Random forest classifier
The random forest classifier is a popular choice in classification problems, especially when overfitting is a concern. As an ensemble model, the random forest does a good job of minimizing bias by averaging out the contributions of many hundreds or thousands of predictors.
Show code
rf_params = dict(
n_estimators=1000,
max_features='auto',
bootstrap=True,
n_jobs=-1,
random_state=0
)
rf_pipeline = NLPipeline(
vectorizer=vectorizer,
resampler=MLSOL(perc_gen_instances=0.3, k=5, random_state=0),
classifier=BinaryRelevance(
RandomForestClassifier(**rf_params),
require_dense=[False, True]
)
)
rf_mlc = multilabel_pipeline_cross_val(rf_pipeline, X[::3], y[::3], labels=genres, verbose=2)
rf_mlc.plot_roc_curve()
plt.show()
rf_mlc.plot_precision_recall_curve()
plt.show()-------- Fold 1/3 100%|█████████████████████████████████████████████████████████████████████████████| 7309/7309 [00:31<00:00, 230.13it/s] Binary classification metrics: label: black balanced_accuracy 0.522 precision 0.756 recall 0.048 f1 0.090 confusion matrix: [[ 10090 32] [ 1960 99]] label: death balanced_accuracy 0.600 precision 0.622 recall 0.298 f1 0.403 confusion matrix: [[ 7101 778] [ 3020 1282]] label: heavy balanced_accuracy 0.507 precision 0.885 recall 0.014 f1 0.027 confusion matrix: [[ 10508 3] [ 1647 23]] label: power balanced_accuracy 0.504 precision 0.850 recall 0.008 f1 0.015 confusion matrix: [[ 9948 3] [ 2213 17]] label: thrash balanced_accuracy 0.501 precision 1.000 recall 0.002 f1 0.004 confusion matrix: [[ 10243 0] [ 1934 4]] Average binary classification scores: balanced_accuracy 0.53 +/- 0.07 precision 0.82 +/- 0.25 recall 0.07 +/- 0.23 f1 0.11 +/- 0.30 Multi-label classification metrics: accuracy 0.12 precision 0.64 recall 0.13 f1 0.21 hamming loss 0.95 ROC AUC scores: black : 0.778 death : 0.713 heavy : 0.719 power : 0.761 thrash : 0.662 macro-avg : 0.727 +/- 0.040 -------- Fold 2/3 100%|█████████████████████████████████████████████████████████████████████████████| 7308/7308 [00:32<00:00, 227.20it/s] Binary classification metrics: label: black balanced_accuracy 0.521 precision 0.843 recall 0.044 f1 0.084 confusion matrix: [[ 10106 17] [ 1968 91]] label: death balanced_accuracy 0.603 precision 0.612 recall 0.316 f1 0.416 confusion matrix: [[ 7020 861] [ 2944 1357]] label: heavy balanced_accuracy 0.507 precision 0.828 recall 0.014 f1 0.028 confusion matrix: [[ 10507 5] [ 1646 24]] label: power balanced_accuracy 0.503 precision 0.765 recall 0.006 f1 0.012 confusion matrix: [[ 9947 4] [ 2218 13]] label: thrash balanced_accuracy 0.501 precision 0.750 recall 0.003 f1 0.006 confusion matrix: [[ 10242 2] [ 1932 6]] Average binary classification scores: balanced_accuracy 0.53 +/- 0.08 precision 0.76 +/- 0.16 recall 0.08 +/- 0.24 f1 0.11 +/- 0.31 Multi-label classification metrics: accuracy 0.13 precision 0.63 recall 0.13 f1 0.22 hamming loss 0.95 ROC AUC scores: black : 0.775 death : 0.707 heavy : 0.730 power : 0.762 thrash : 0.668 macro-avg : 0.728 +/- 0.038 -------- Fold 3/3 100%|█████████████████████████████████████████████████████████████████████████████| 7308/7308 [00:32<00:00, 227.88it/s] Binary classification metrics: label: black balanced_accuracy 0.518 precision 0.814 recall 0.038 f1 0.073 confusion matrix: [[ 10104 18] [ 1981 79]] label: death balanced_accuracy 0.602 precision 0.620 recall 0.306 f1 0.410 confusion matrix: [[ 7072 808] [ 2986 1316]] label: heavy balanced_accuracy 0.506 precision 0.880 recall 0.013 f1 0.026 confusion matrix: [[ 10509 3] [ 1648 22]] label: power balanced_accuracy 0.503 precision 0.889 recall 0.007 f1 0.014 confusion matrix: [[ 9949 2] [ 2215 16]] label: thrash balanced_accuracy 0.502 precision 0.833 recall 0.005 f1 0.010 confusion matrix: [[ 10243 2] [ 1927 10]] Average binary classification scores: balanced_accuracy 0.53 +/- 0.08 precision 0.81 +/- 0.20 recall 0.07 +/- 0.23 f1 0.11 +/- 0.31 Multi-label classification metrics: accuracy 0.12 precision 0.63 recall 0.13 f1 0.21 hamming loss 0.95 ROC AUC scores: black : 0.774 death : 0.718 heavy : 0.739 power : 0.759 thrash : 0.670 macro-avg : 0.732 +/- 0.036 ------------------------ Cross-validation results Binary classification metrics: label: black balanced_accuracy 0.706 precision 0.345 recall 0.672 f1 0.456 confusion matrix: [[ 22469 7898] [ 2025 4153]] label: death balanced_accuracy 0.654 precision 0.504 recall 0.664 f1 0.573 confusion matrix: [[ 15218 8422] [ 4340 8565]] label: heavy balanced_accuracy 0.669 precision 0.242 recall 0.673 f1 0.356 confusion matrix: [[ 20956 10579] [ 1638 3372]] label: power balanced_accuracy 0.694 precision 0.334 recall 0.701 f1 0.453 confusion matrix: [[ 20521 9332] [ 2002 4690]] label: thrash balanced_accuracy 0.622 precision 0.244 recall 0.588 f1 0.345 confusion matrix: [[ 20136 10596] [ 2393 3420]] Average binary classification scores: balanced_accuracy 0.67 +/- 0.06 precision 0.33 +/- 0.19 recall 0.66 +/- 0.08 f1 0.44 +/- 0.17 Multi-label classification metrics: accuracy 0.32 precision 0.36 recall 0.67 f1 0.47 hamming loss 1.62 ROC AUC scores: black : 0.775 death : 0.713 heavy : 0.729 power : 0.761 thrash : 0.667 macro-avg : 0.729 +/- 0.038
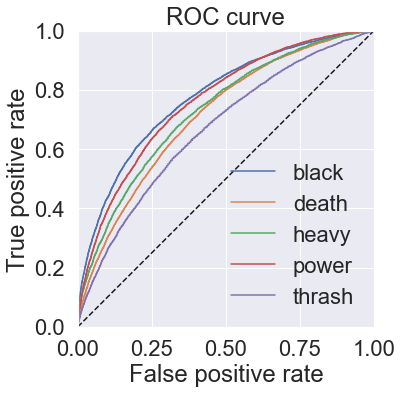
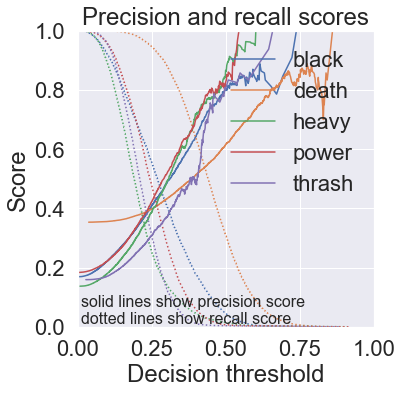
Show code
print(rf_mlc.threshold)
rf_pipeline.fit(X, y, labels=genres)
rf_pipeline.set_threshold(rf_mlc.threshold)
for text in test_corpus:
print(text)
rf_pipeline.classify_text(text)
print()[0.20501235 0.38917857 0.15568 0.19583333 0.19222251] 100%|████████████████████████████████████████████████████████████████████████████| 32889/32889 [10:16<00:00, 53.37it/s] Classification: NONE Individual label probabilities: death 22% thrash 19% heavy 7% black 5% power 4% satan Classification: BLACK, DEATH Individual label probabilities: black 84% death 40% thrash 9% heavy 5% power 1% flesh Classification: BLACK Individual label probabilities: black 49% death 6% thrash 0% heavy 0% power 0% fight Classification: NONE Individual label probabilities: thrash 6% death 6% black 6% power 3% heavy 1% attack Classification: NONE Individual label probabilities: death 15% power 6% thrash 5% heavy 4% black 3%
Feature importances
Show code
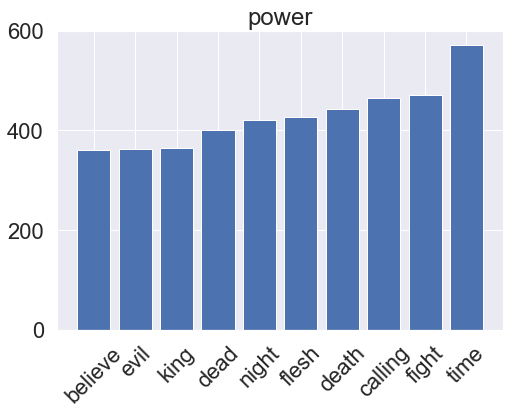
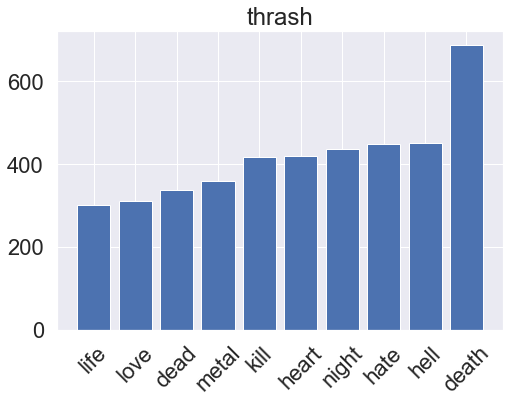
for genre, clf in zip(genres, rf_pipeline.classifier.classifiers_):
fi = clf.feature_importances_
fi_top = fi.argsort()[-10:]
x_vals = range(len(fi_top))
plt.bar(x_vals, fi[fi_top])
plt.title(genre)
plt.xticks(x_vals, np.array(vectorizer.get_feature_names_out())[fi_top], rotation=45)
plt.show()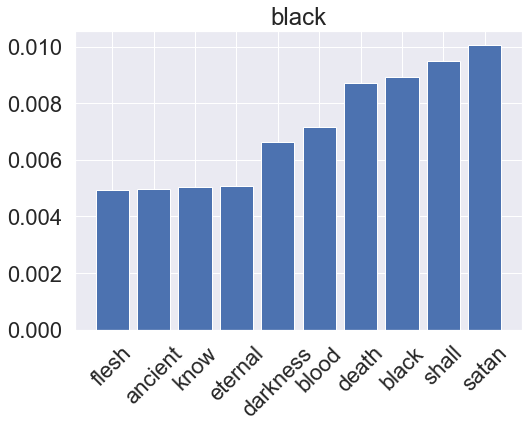
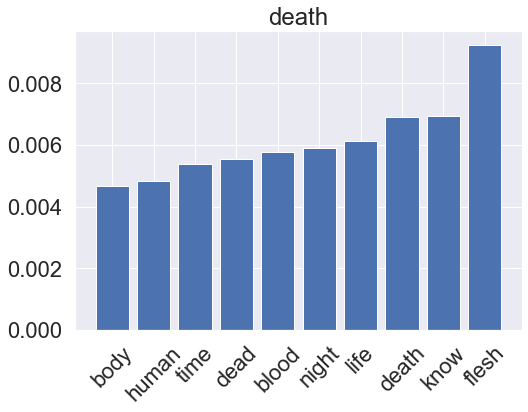
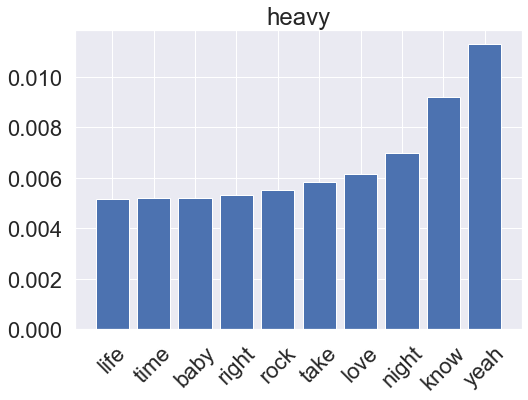
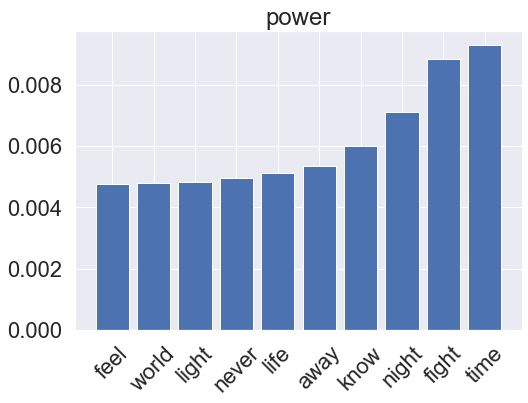
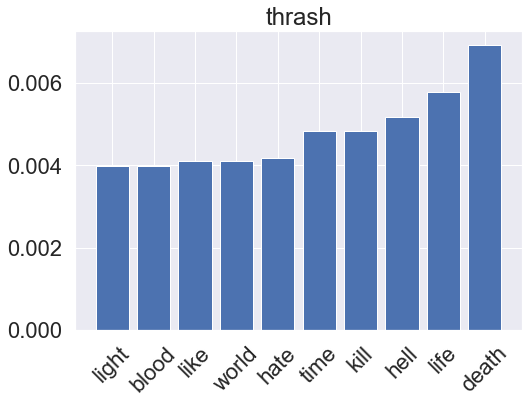
Gradient boosting model
Going beyond random forests, gradient boosting models (GBMs) expand on the idea of ensembling in a way that typically outperforms random forests. The idea is to ensemble many weak estimators, in this case decision trees, sequentially by fitting each one to the residual of the previous. There are a few good GBM libraries out there: I’m using LightGBM here, but other popular choices include XGBoost, CatBoost, and sci-kit learn’s implementation.
Show code
gbm_params = dict(
boosting_type='dart',
n_estimators=1000,
num_leaves=63,
n_jobs=-1,
random_state=0
)
gbm_pipeline = NLPipeline(
vectorizer=vectorizer,
resampler=MLSOL(perc_gen_instances=0.3, k=5, random_state=0),
classifier=BinaryRelevance(
lgb.LGBMClassifier(**gbm_params),
require_dense=[False, True]
)
)
gbm_mlc = multilabel_pipeline_cross_val(gbm_pipeline, X[::3], y[::3], labels=genres, verbose=2)
gbm_mlc.plot_roc_curve()
plt.show()
gbm_mlc.plot_precision_recall_curve()
plt.show()-------- Fold 1/3 100%|█████████████████████████████████████████████████████████████████████████████| 7308/7308 [00:31<00:00, 229.44it/s] Binary classification metrics: label: black balanced_accuracy 0.590 precision 0.626 recall 0.204 f1 0.308 confusion matrix: [[ 9871 252] [ 1638 421]] label: death balanced_accuracy 0.610 precision 0.580 recall 0.364 f1 0.447 confusion matrix: [[ 6747 1134] [ 2737 1564]] label: heavy balanced_accuracy 0.548 precision 0.607 recall 0.107 f1 0.182 confusion matrix: [[ 10396 116] [ 1491 179]] label: power balanced_accuracy 0.583 precision 0.619 recall 0.193 f1 0.295 confusion matrix: [[ 9687 265] [ 1799 431]] label: thrash balanced_accuracy 0.514 precision 0.520 recall 0.034 f1 0.063 confusion matrix: [[ 10184 60] [ 1873 65]] Average binary classification scores: balanced_accuracy 0.57 +/- 0.07 precision 0.59 +/- 0.08 recall 0.18 +/- 0.22 f1 0.26 +/- 0.26 Multi-label classification metrics: accuracy 0.21 precision 0.60 recall 0.23 f1 0.33 hamming loss 0.93 ROC AUC scores: black : 0.789 death : 0.706 heavy : 0.749 power : 0.785 thrash : 0.670 macro-avg : 0.740 +/- 0.046 -------- Fold 2/3 100%|█████████████████████████████████████████████████████████████████████████████| 7309/7309 [00:32<00:00, 225.27it/s] Binary classification metrics: label: black balanced_accuracy 0.586 precision 0.574 recall 0.203 f1 0.299 confusion matrix: [[ 9813 309] [ 1642 417]] label: death balanced_accuracy 0.613 precision 0.584 recall 0.370 f1 0.453 confusion matrix: [[ 6748 1131] [ 2712 1590]] label: heavy balanced_accuracy 0.548 precision 0.630 recall 0.106 f1 0.181 confusion matrix: [[ 10407 104] [ 1493 177]] label: power balanced_accuracy 0.580 precision 0.601 recall 0.188 f1 0.287 confusion matrix: [[ 9671 279] [ 1811 420]] label: thrash balanced_accuracy 0.510 precision 0.420 recall 0.028 f1 0.053 confusion matrix: [[ 10168 76] [ 1882 55]] Average binary classification scores: balanced_accuracy 0.57 +/- 0.07 precision 0.56 +/- 0.15 recall 0.18 +/- 0.23 f1 0.25 +/- 0.27 Multi-label classification metrics: accuracy 0.21 precision 0.59 recall 0.23 f1 0.33 hamming loss 0.94 ROC AUC scores: black : 0.776 death : 0.707 heavy : 0.758 power : 0.779 thrash : 0.674 macro-avg : 0.739 +/- 0.041 -------- Fold 3/3 100%|█████████████████████████████████████████████████████████████████████████████| 7308/7308 [00:31<00:00, 231.01it/s] Binary classification metrics: label: black balanced_accuracy 0.592 precision 0.604 recall 0.213 f1 0.315 confusion matrix: [[ 9835 287] [ 1622 438]] label: death balanced_accuracy 0.619 precision 0.588 recall 0.386 f1 0.466 confusion matrix: [[ 6717 1163] [ 2643 1659]] label: heavy balanced_accuracy 0.549 precision 0.610 recall 0.110 f1 0.186 confusion matrix: [[ 10395 117] [ 1487 183]] label: power balanced_accuracy 0.585 precision 0.603 recall 0.200 f1 0.300 confusion matrix: [[ 9657 294] [ 1785 446]] label: thrash balanced_accuracy 0.516 precision 0.446 recall 0.042 f1 0.077 confusion matrix: [[ 10142 102] [ 1856 82]] Average binary classification scores: balanced_accuracy 0.57 +/- 0.07 precision 0.57 +/- 0.13 recall 0.19 +/- 0.23 f1 0.27 +/- 0.26 Multi-label classification metrics: accuracy 0.22 precision 0.59 recall 0.24 f1 0.35 hamming loss 0.93 ROC AUC scores: black : 0.785 death : 0.709 heavy : 0.768 power : 0.790 thrash : 0.656 macro-avg : 0.742 +/- 0.052 ------------------------ Cross-validation results Binary classification metrics: label: black balanced_accuracy 0.713 precision 0.331 recall 0.722 f1 0.454 confusion matrix: [[ 21367 9000] [ 1718 4460]] label: death balanced_accuracy 0.649 precision 0.501 recall 0.654 f1 0.567 confusion matrix: [[ 15217 8423] [ 4465 8440]] label: heavy balanced_accuracy 0.690 precision 0.260 recall 0.692 f1 0.378 confusion matrix: [[ 21665 9870] [ 1541 3469]] label: power balanced_accuracy 0.710 precision 0.351 recall 0.715 f1 0.471 confusion matrix: [[ 21003 8850] [ 1904 4788]] label: thrash balanced_accuracy 0.620 precision 0.237 recall 0.614 f1 0.342 confusion matrix: [[ 19254 11478] [ 2241 3572]] Average binary classification scores: balanced_accuracy 0.68 +/- 0.07 precision 0.34 +/- 0.19 recall 0.68 +/- 0.08 f1 0.44 +/- 0.16 Multi-label classification metrics: accuracy 0.33 precision 0.36 recall 0.69 f1 0.47 hamming loss 1.63 ROC AUC scores: black : 0.783 death : 0.707 heavy : 0.758 power : 0.784 thrash : 0.667 macro-avg : 0.740 +/- 0.046
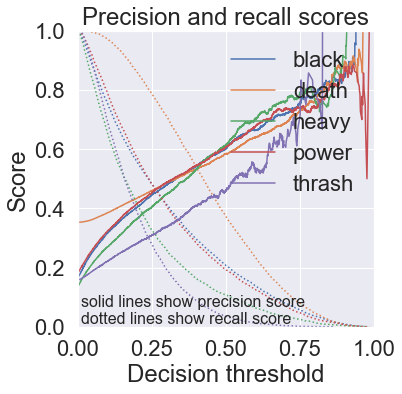
Show code
print(gbm_mlc.threshold)
gbm_pipeline.fit(X, y, labels=genres)
gbm_pipeline.set_threshold(gbm_mlc.threshold)
for text in test_corpus:
print(text)
gbm_pipeline.classify_text(text)
print()[0.11440158 0.33268319 0.08962132 0.12956028 0.12367164] 100%|████████████████████████████████████████████████████████████████████████████| 32889/32889 [09:55<00:00, 55.24it/s] Classification: DEATH, THRASH, BLACK, HEAVY Individual label probabilities: death 35% thrash 22% black 19% heavy 11% power 4% satan Classification: BLACK, THRASH, HEAVY Individual label probabilities: black 65% death 33% thrash 20% heavy 10% power 2% flesh Classification: DEATH, BLACK Individual label probabilities: death 53% black 23% thrash 12% heavy 6% power 2% fight Classification: NONE Individual label probabilities: death 27% thrash 23% heavy 15% black 15% power 9% attack Classification: THRASH, BLACK, HEAVY Individual label probabilities: thrash 29% death 27% black 19% heavy 11% power 5%
Feature importances
Show code
for genre, clf in zip(genres, gbm_pipeline.classifier.classifiers_):
fi = clf.feature_importances_
fi_top = fi.argsort()[-10:]
x_vals = range(len(fi_top))
plt.bar(x_vals, fi[fi_top])
plt.title(genre)
plt.xticks(x_vals, np.array(vectorizer.get_feature_names_out())[fi_top], rotation=45)
plt.show()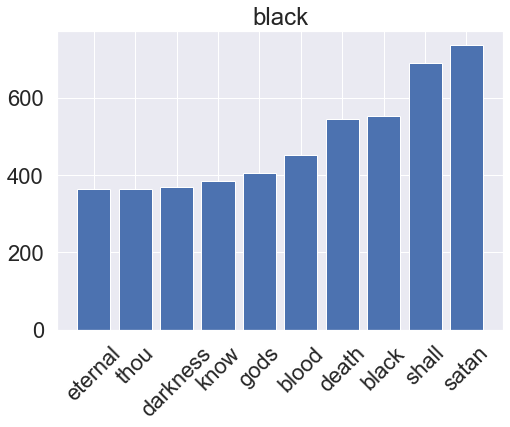
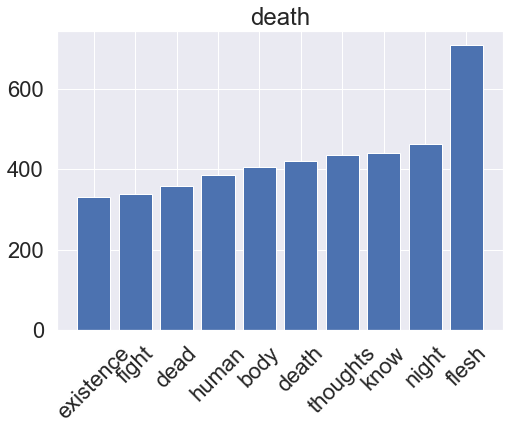
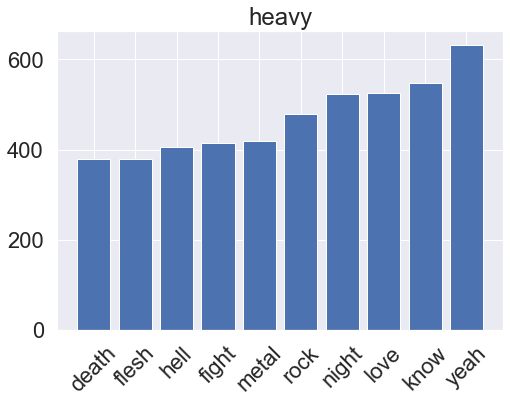
Neural network
Show code
def create_keras_model(input_dim, output_dim):
model = Sequential()
model.add(layers.Dense(1024, input_dim=input_dim, activation='relu'))
# model.add(layers.Dropout(rate=0.2))
# model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(output_dim, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['binary_accuracy'])
return modelkeras_params = dict(
input_dim=vectorizer.max_features,
output_dim=y.shape[1],
epochs=64,
batch_size=256,
)
callbacks = [
EarlyStopping(
monitor='val_loss',
min_delta=0,
patience=10,
verbose=0,
mode='auto',
baseline=None,
restore_best_weights=True
)
]
keras_pipeline = NLPipeline(
vectorizer=vectorizer,
resampler=MLSOL(perc_gen_instances=0.3, k=5, random_state=0),
classifier=KerasClassifier(create_keras_model, **keras_params),
pad_features=True,
)
keras_mlc = multilabel_pipeline_cross_val(keras_pipeline, X[::3], y[::3], labels=genres, verbose=2, keras=True, callbacks=callbacks)
keras_mlc.plot_roc_curve()
plt.show()
keras_mlc.plot_precision_recall_curve()
plt.show()Show output
C:\Users\philn\AppData\Local\Temp\ipykernel_1392\2768025053.py:23: DeprecationWarning: KerasClassifier is deprecated, use Sci-Keras (https://github.com/adriangb/scikeras) instead. classifier=KerasClassifier(create_keras_model, **keras_params), -------- Fold 1/3 1%|▋ | 69/7308 [00:00<00:33, 215.35it/s]E:\Projects\metallyrics\analyses\lyrics\notebooks\../scripts\mlsol.py:115: RuntimeWarning: invalid value encountered in double_scalars cd = dist_seed / (dist_seed - dist_reference) 100%|█████████████████████████████████████████████████████████████████████████████| 7308/7308 [00:33<00:00, 219.24it/s] Epoch 1/64 99/99 [==============================] - 1s 9ms/step - loss: 0.4795 - binary_accuracy: 0.7983 - val_loss: 0.5016 - val_binary_accuracy: 0.7657 Epoch 2/64 99/99 [==============================] - 1s 8ms/step - loss: 0.4123 - binary_accuracy: 0.8160 - val_loss: 0.4840 - val_binary_accuracy: 0.7720 Epoch 3/64 99/99 [==============================] - 1s 8ms/step - loss: 0.3983 - binary_accuracy: 0.8226 - val_loss: 0.4772 - val_binary_accuracy: 0.7731 Epoch 4/64 99/99 [==============================] - 1s 8ms/step - loss: 0.3894 - binary_accuracy: 0.8265 - val_loss: 0.4772 - val_binary_accuracy: 0.7733 Epoch 5/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3803 - binary_accuracy: 0.8314 - val_loss: 0.4731 - val_binary_accuracy: 0.7752 Epoch 6/64 99/99 [==============================] - 1s 8ms/step - loss: 0.3689 - binary_accuracy: 0.8380 - val_loss: 0.4655 - val_binary_accuracy: 0.7778 Epoch 7/64 99/99 [==============================] - 1s 10ms/step - loss: 0.3538 - binary_accuracy: 0.8471 - val_loss: 0.4592 - val_binary_accuracy: 0.7807 Epoch 8/64 99/99 [==============================] - 1s 10ms/step - loss: 0.3347 - binary_accuracy: 0.8598 - val_loss: 0.4537 - val_binary_accuracy: 0.7825 Epoch 9/64 99/99 [==============================] - 1s 8ms/step - loss: 0.3128 - binary_accuracy: 0.8733 - val_loss: 0.4404 - val_binary_accuracy: 0.7918 Epoch 10/64 99/99 [==============================] - 1s 8ms/step - loss: 0.2885 - binary_accuracy: 0.8885 - val_loss: 0.4299 - val_binary_accuracy: 0.7966 Epoch 11/64 99/99 [==============================] - 1s 8ms/step - loss: 0.2635 - binary_accuracy: 0.9034 - val_loss: 0.4201 - val_binary_accuracy: 0.8021 Epoch 12/64 99/99 [==============================] - 1s 7ms/step - loss: 0.2388 - binary_accuracy: 0.9169 - val_loss: 0.4095 - val_binary_accuracy: 0.8077 Epoch 13/64 99/99 [==============================] - ETA: 0s - loss: 0.2144 - binary_accuracy: 0.929 - 1s 7ms/step - loss: 0.2147 - binary_accuracy: 0.9297 - val_loss: 0.4003 - val_binary_accuracy: 0.8123 Epoch 14/64 99/99 [==============================] - 1s 8ms/step - loss: 0.1920 - binary_accuracy: 0.9416 - val_loss: 0.3966 - val_binary_accuracy: 0.8137 Epoch 15/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1707 - binary_accuracy: 0.9516 - val_loss: 0.3876 - val_binary_accuracy: 0.8187 Epoch 16/64 99/99 [==============================] - 1s 8ms/step - loss: 0.1509 - binary_accuracy: 0.9615 - val_loss: 0.3789 - val_binary_accuracy: 0.8241 Epoch 17/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1330 - binary_accuracy: 0.9700 - val_loss: 0.3744 - val_binary_accuracy: 0.8257 Epoch 18/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1168 - binary_accuracy: 0.9766 - val_loss: 0.3683 - val_binary_accuracy: 0.8296 Epoch 19/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1021 - binary_accuracy: 0.9831 - val_loss: 0.3665 - val_binary_accuracy: 0.8313 Epoch 20/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0893 - binary_accuracy: 0.9877 - val_loss: 0.3615 - val_binary_accuracy: 0.8341 Epoch 21/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0780 - binary_accuracy: 0.9915 - val_loss: 0.3600 - val_binary_accuracy: 0.8355 Epoch 22/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0680 - binary_accuracy: 0.9939 - val_loss: 0.3562 - val_binary_accuracy: 0.8388 Epoch 23/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0594 - binary_accuracy: 0.9960 - val_loss: 0.3567 - val_binary_accuracy: 0.8393 Epoch 24/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0521 - binary_accuracy: 0.9971 - val_loss: 0.3555 - val_binary_accuracy: 0.8395 Epoch 25/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0457 - binary_accuracy: 0.9979 - val_loss: 0.3556 - val_binary_accuracy: 0.8410 Epoch 26/64 99/99 [==============================] - 1s 8ms/step - loss: 0.0403 - binary_accuracy: 0.9984 - val_loss: 0.3548 - val_binary_accuracy: 0.8424 Epoch 27/64 99/99 [==============================] - 1s 8ms/step - loss: 0.0355 - binary_accuracy: 0.9988 - val_loss: 0.3559 - val_binary_accuracy: 0.8434 Epoch 28/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0315 - binary_accuracy: 0.9990 - val_loss: 0.3552 - val_binary_accuracy: 0.8451 Epoch 29/64 99/99 [==============================] - 1s 8ms/step - loss: 0.0280 - binary_accuracy: 0.9993 - val_loss: 0.3572 - val_binary_accuracy: 0.8446 Epoch 30/64 99/99 [==============================] - 1s 8ms/step - loss: 0.0250 - binary_accuracy: 0.9994 - val_loss: 0.3584 - val_binary_accuracy: 0.8445 Epoch 31/64 99/99 [==============================] - 1s 8ms/step - loss: 0.0224 - binary_accuracy: 0.9995 - val_loss: 0.3598 - val_binary_accuracy: 0.8451 Epoch 32/64 99/99 [==============================] - 1s 8ms/step - loss: 0.0201 - binary_accuracy: 0.9996 - val_loss: 0.3624 - val_binary_accuracy: 0.8456 Epoch 33/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0181 - binary_accuracy: 0.9997 - val_loss: 0.3638 - val_binary_accuracy: 0.8463 Epoch 34/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0164 - binary_accuracy: 0.9997 - val_loss: 0.3675 - val_binary_accuracy: 0.8461 Epoch 35/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0149 - binary_accuracy: 0.9998 - val_loss: 0.3667 - val_binary_accuracy: 0.8472 Epoch 36/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0135 - binary_accuracy: 0.9998 - val_loss: 0.3687 - val_binary_accuracy: 0.8476 Binary classification metrics: label: black balanced_accuracy 0.618 precision 0.511 recall 0.292 f1 0.372 confusion matrix: [[ 9548 575] [ 1457 602]] label: death balanced_accuracy 0.620 precision 0.551 recall 0.430 f1 0.483 confusion matrix: [[ 6373 1507] [ 2451 1851]] label: heavy balanced_accuracy 0.589 precision 0.467 recall 0.218 f1 0.297 confusion matrix: [[ 10096 416] [ 1306 364]] label: power balanced_accuracy 0.627 precision 0.549 recall 0.312 f1 0.397 confusion matrix: [[ 9379 572] [ 1536 695]] label: thrash balanced_accuracy 0.539 precision 0.354 recall 0.118 f1 0.177 confusion matrix: [[ 9826 418] [ 1709 229]] Average binary classification scores: balanced_accuracy 0.60 +/- 0.07 precision 0.49 +/- 0.15 recall 0.27 +/- 0.21 f1 0.35 +/- 0.21 Multi-label classification metrics: accuracy 0.27 precision 0.52 recall 0.32 f1 0.40 hamming loss 0.98 ROC AUC scores: black : 0.769 death : 0.695 heavy : 0.748 power : 0.774 thrash : 0.651 macro-avg : 0.727 +/- 0.047 -------- Fold 2/3 C:\Users\philn\AppData\Roaming\Python\Python39\site-packages\sklearn\utils\deprecation.py:87: FutureWarning: Function get_feature_names is deprecated; get_feature_names is deprecated in 1.0 and will be removed in 1.2. Please use get_feature_names_out instead. warnings.warn(msg, category=FutureWarning) 100%|█████████████████████████████████████████████████████████████████████████████| 7309/7309 [00:33<00:00, 216.46it/s] Epoch 1/64 99/99 [==============================] - 1s 8ms/step - loss: 0.4786 - binary_accuracy: 0.8002 - val_loss: 0.4989 - val_binary_accuracy: 0.7708 Epoch 2/64 99/99 [==============================] - 1s 7ms/step - loss: 0.4127 - binary_accuracy: 0.8173 - val_loss: 0.4822 - val_binary_accuracy: 0.7737 Epoch 3/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3983 - binary_accuracy: 0.8229 - val_loss: 0.4752 - val_binary_accuracy: 0.7775 Epoch 4/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3896 - binary_accuracy: 0.8268 - val_loss: 0.4706 - val_binary_accuracy: 0.7783 Epoch 5/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3801 - binary_accuracy: 0.8320 - val_loss: 0.4693 - val_binary_accuracy: 0.7780 Epoch 6/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3685 - binary_accuracy: 0.8387 - val_loss: 0.4644 - val_binary_accuracy: 0.7819 Epoch 7/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3532 - binary_accuracy: 0.8483 - val_loss: 0.4560 - val_binary_accuracy: 0.7854 Epoch 8/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3342 - binary_accuracy: 0.8606 - val_loss: 0.4470 - val_binary_accuracy: 0.7902 Epoch 9/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3116 - binary_accuracy: 0.8745 - val_loss: 0.4367 - val_binary_accuracy: 0.7953 Epoch 10/64 99/99 [==============================] - 1s 7ms/step - loss: 0.2873 - binary_accuracy: 0.8890 - val_loss: 0.4250 - val_binary_accuracy: 0.8010 Epoch 11/64 99/99 [==============================] - 1s 7ms/step - loss: 0.2621 - binary_accuracy: 0.9044 - val_loss: 0.4184 - val_binary_accuracy: 0.8037 Epoch 12/64 99/99 [==============================] - 1s 7ms/step - loss: 0.2371 - binary_accuracy: 0.9177 - val_loss: 0.4056 - val_binary_accuracy: 0.8099 Epoch 13/64 99/99 [==============================] - 1s 7ms/step - loss: 0.2129 - binary_accuracy: 0.9302 - val_loss: 0.3965 - val_binary_accuracy: 0.8153 Epoch 14/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1899 - binary_accuracy: 0.9420 - val_loss: 0.3883 - val_binary_accuracy: 0.8200 Epoch 15/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1683 - binary_accuracy: 0.9533 - val_loss: 0.3819 - val_binary_accuracy: 0.8217 Epoch 16/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1487 - binary_accuracy: 0.9627 - val_loss: 0.3752 - val_binary_accuracy: 0.8283 Epoch 17/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1307 - binary_accuracy: 0.9713 - val_loss: 0.3685 - val_binary_accuracy: 0.8311 Epoch 18/64 99/99 [==============================] - 1s 8ms/step - loss: 0.1146 - binary_accuracy: 0.9785 - val_loss: 0.3634 - val_binary_accuracy: 0.8333 Epoch 19/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1001 - binary_accuracy: 0.9843 - val_loss: 0.3594 - val_binary_accuracy: 0.8359 Epoch 20/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0875 - binary_accuracy: 0.9885 - val_loss: 0.3535 - val_binary_accuracy: 0.8379 Epoch 21/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0763 - binary_accuracy: 0.9921 - val_loss: 0.3509 - val_binary_accuracy: 0.8405 Epoch 22/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0667 - binary_accuracy: 0.9945 - val_loss: 0.3500 - val_binary_accuracy: 0.8397 Epoch 23/64 99/99 [==============================] - 1s 8ms/step - loss: 0.0582 - binary_accuracy: 0.9960 - val_loss: 0.3457 - val_binary_accuracy: 0.8437 Epoch 24/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0511 - binary_accuracy: 0.9971 - val_loss: 0.3444 - val_binary_accuracy: 0.8445 Epoch 25/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0450 - binary_accuracy: 0.9978 - val_loss: 0.3456 - val_binary_accuracy: 0.8455 Epoch 26/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0396 - binary_accuracy: 0.9984 - val_loss: 0.3493 - val_binary_accuracy: 0.8446 Epoch 27/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0350 - binary_accuracy: 0.9988 - val_loss: 0.3496 - val_binary_accuracy: 0.8446 Epoch 28/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0311 - binary_accuracy: 0.9990 - val_loss: 0.3468 - val_binary_accuracy: 0.8463 Epoch 29/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0277 - binary_accuracy: 0.9992 - val_loss: 0.3500 - val_binary_accuracy: 0.8471 Epoch 30/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0247 - binary_accuracy: 0.9994 - val_loss: 0.3488 - val_binary_accuracy: 0.8476 Epoch 31/64 99/99 [==============================] - 1s 8ms/step - loss: 0.0222 - binary_accuracy: 0.9995 - val_loss: 0.3504 - val_binary_accuracy: 0.8486 Epoch 32/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0199 - binary_accuracy: 0.9996 - val_loss: 0.3537 - val_binary_accuracy: 0.8491 Epoch 33/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0180 - binary_accuracy: 0.9997 - val_loss: 0.3521 - val_binary_accuracy: 0.8497 Epoch 34/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0163 - binary_accuracy: 0.9997 - val_loss: 0.3543 - val_binary_accuracy: 0.8501 Binary classification metrics: label: black balanced_accuracy 0.630 precision 0.549 recall 0.312 f1 0.398 confusion matrix: [[ 9593 528] [ 1417 643]] label: death balanced_accuracy 0.622 precision 0.566 recall 0.419 f1 0.482 confusion matrix: [[ 6494 1385] [ 2498 1804]] label: heavy balanced_accuracy 0.581 precision 0.459 recall 0.199 f1 0.277 confusion matrix: [[ 10120 391] [ 1338 332]] label: power balanced_accuracy 0.626 precision 0.531 recall 0.314 f1 0.395 confusion matrix: [[ 9332 619] [ 1529 701]] label: thrash balanced_accuracy 0.548 precision 0.357 recall 0.145 f1 0.206 confusion matrix: [[ 9739 505] [ 1657 280]] Average binary classification scores: balanced_accuracy 0.60 +/- 0.06 precision 0.49 +/- 0.15 recall 0.28 +/- 0.19 f1 0.35 +/- 0.20 Multi-label classification metrics: accuracy 0.27 precision 0.53 recall 0.32 f1 0.40 hamming loss 0.97 ROC AUC scores: black : 0.772 death : 0.699 heavy : 0.749 power : 0.776 thrash : 0.654 macro-avg : 0.730 +/- 0.047 -------- Fold 3/3 C:\Users\philn\AppData\Roaming\Python\Python39\site-packages\sklearn\utils\deprecation.py:87: FutureWarning: Function get_feature_names is deprecated; get_feature_names is deprecated in 1.0 and will be removed in 1.2. Please use get_feature_names_out instead. warnings.warn(msg, category=FutureWarning) 100%|█████████████████████████████████████████████████████████████████████████████| 7308/7308 [00:33<00:00, 221.10it/s] Epoch 1/64 99/99 [==============================] - 1s 8ms/step - loss: 0.4760 - binary_accuracy: 0.8021 - val_loss: 0.4779 - val_binary_accuracy: 0.7830 Epoch 2/64 99/99 [==============================] - 1s 7ms/step - loss: 0.4108 - binary_accuracy: 0.8172 - val_loss: 0.4525 - val_binary_accuracy: 0.7914 Epoch 3/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3968 - binary_accuracy: 0.8229 - val_loss: 0.4451 - val_binary_accuracy: 0.7927 Epoch 4/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3881 - binary_accuracy: 0.8269 - val_loss: 0.4422 - val_binary_accuracy: 0.7953 Epoch 5/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3792 - binary_accuracy: 0.8326 - val_loss: 0.4322 - val_binary_accuracy: 0.7980 Epoch 6/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3679 - binary_accuracy: 0.8392 - val_loss: 0.4278 - val_binary_accuracy: 0.8004 Epoch 7/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3532 - binary_accuracy: 0.8482 - val_loss: 0.4195 - val_binary_accuracy: 0.8036 Epoch 8/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3344 - binary_accuracy: 0.8599 - val_loss: 0.4094 - val_binary_accuracy: 0.8079 Epoch 9/64 99/99 [==============================] - 1s 7ms/step - loss: 0.3131 - binary_accuracy: 0.8733 - val_loss: 0.4008 - val_binary_accuracy: 0.8137 Epoch 10/64 99/99 [==============================] - 1s 7ms/step - loss: 0.2897 - binary_accuracy: 0.8880 - val_loss: 0.3889 - val_binary_accuracy: 0.8198 Epoch 11/64 99/99 [==============================] - 1s 7ms/step - loss: 0.2651 - binary_accuracy: 0.9031 - val_loss: 0.3752 - val_binary_accuracy: 0.8255 Epoch 12/64 99/99 [==============================] - 1s 8ms/step - loss: 0.2407 - binary_accuracy: 0.9159 - val_loss: 0.3690 - val_binary_accuracy: 0.8286 Epoch 13/64 99/99 [==============================] - 1s 7ms/step - loss: 0.2173 - binary_accuracy: 0.9289 - val_loss: 0.3595 - val_binary_accuracy: 0.8324 Epoch 14/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1950 - binary_accuracy: 0.9394 - val_loss: 0.3509 - val_binary_accuracy: 0.8373 Epoch 15/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1740 - binary_accuracy: 0.9502 - val_loss: 0.3433 - val_binary_accuracy: 0.8411 Epoch 16/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1545 - binary_accuracy: 0.9596 - val_loss: 0.3342 - val_binary_accuracy: 0.8453 Epoch 17/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1366 - binary_accuracy: 0.9684 - val_loss: 0.3278 - val_binary_accuracy: 0.8480 Epoch 18/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1203 - binary_accuracy: 0.9761 - val_loss: 0.3257 - val_binary_accuracy: 0.8483 Epoch 19/64 99/99 [==============================] - 1s 7ms/step - loss: 0.1056 - binary_accuracy: 0.9821 - val_loss: 0.3196 - val_binary_accuracy: 0.8509 Epoch 20/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0926 - binary_accuracy: 0.9870 - val_loss: 0.3139 - val_binary_accuracy: 0.8525 Epoch 21/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0809 - binary_accuracy: 0.9912 - val_loss: 0.3138 - val_binary_accuracy: 0.8523 Epoch 22/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0709 - binary_accuracy: 0.9937 - val_loss: 0.3078 - val_binary_accuracy: 0.8555 Epoch 23/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0620 - binary_accuracy: 0.9959 - val_loss: 0.3057 - val_binary_accuracy: 0.8579 Epoch 24/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0544 - binary_accuracy: 0.9972 - val_loss: 0.3027 - val_binary_accuracy: 0.8590 Epoch 25/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0478 - binary_accuracy: 0.9981 - val_loss: 0.3041 - val_binary_accuracy: 0.8579 Epoch 26/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0421 - binary_accuracy: 0.9986 - val_loss: 0.3022 - val_binary_accuracy: 0.8590 Epoch 27/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0372 - binary_accuracy: 0.9989 - val_loss: 0.3002 - val_binary_accuracy: 0.8617 Epoch 28/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0329 - binary_accuracy: 0.9993 - val_loss: 0.2997 - val_binary_accuracy: 0.8620 Epoch 29/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0293 - binary_accuracy: 0.9993 - val_loss: 0.2990 - val_binary_accuracy: 0.8624 Epoch 30/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0262 - binary_accuracy: 0.9994 - val_loss: 0.3006 - val_binary_accuracy: 0.8629 Epoch 31/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0234 - binary_accuracy: 0.9996 - val_loss: 0.3027 - val_binary_accuracy: 0.8628 Epoch 32/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0210 - binary_accuracy: 0.9996 - val_loss: 0.2998 - val_binary_accuracy: 0.8646 Epoch 33/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0188 - binary_accuracy: 0.9997 - val_loss: 0.3010 - val_binary_accuracy: 0.8651 Epoch 34/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0170 - binary_accuracy: 0.9997 - val_loss: 0.3016 - val_binary_accuracy: 0.8653 Epoch 35/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0155 - binary_accuracy: 0.9998 - val_loss: 0.3029 - val_binary_accuracy: 0.8657 Epoch 36/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0140 - binary_accuracy: 0.9998 - val_loss: 0.3052 - val_binary_accuracy: 0.8652 Epoch 37/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0128 - binary_accuracy: 0.9998 - val_loss: 0.3056 - val_binary_accuracy: 0.8658 Epoch 38/64 99/99 [==============================] - 1s 7ms/step - loss: 0.0117 - binary_accuracy: 0.9999 - val_loss: 0.3067 - val_binary_accuracy: 0.8648 Epoch 39/64 99/99 [==============================] - 1s 8ms/step - loss: 0.0106 - binary_accuracy: 0.9999 - val_loss: 0.3079 - val_binary_accuracy: 0.8652 Binary classification metrics: label: black balanced_accuracy 0.632 precision 0.556 recall 0.314 f1 0.401 confusion matrix: [[ 9606 517] [ 1412 647]] label: death balanced_accuracy 0.618 precision 0.551 recall 0.426 f1 0.480 confusion matrix: [[ 6389 1492] [ 2470 1831]] label: heavy balanced_accuracy 0.587 precision 0.482 recall 0.209 f1 0.292 confusion matrix: [[ 10137 375] [ 1321 349]] label: power balanced_accuracy 0.624 precision 0.513 recall 0.316 f1 0.391 confusion matrix: [[ 9282 669] [ 1526 705]] label: thrash balanced_accuracy 0.547 precision 0.372 recall 0.137 f1 0.200 confusion matrix: [[ 9796 448] [ 1673 265]] Average binary classification scores: balanced_accuracy 0.60 +/- 0.06 precision 0.49 +/- 0.13 recall 0.28 +/- 0.20 f1 0.35 +/- 0.19 Multi-label classification metrics: accuracy 0.27 precision 0.53 recall 0.33 f1 0.40 hamming loss 0.98 ROC AUC scores: black : 0.777 death : 0.692 heavy : 0.754 power : 0.769 thrash : 0.663 macro-avg : 0.731 +/- 0.045 ------------------------ Cross-validation results Binary classification metrics: label: black balanced_accuracy 0.699 precision 0.319 recall 0.704 f1 0.439 confusion matrix: [[ 21087 9280] [ 1831 4347]] label: death balanced_accuracy 0.640 precision 0.489 recall 0.652 f1 0.558 confusion matrix: [[ 14833 8807] [ 4494 8411]] label: heavy balanced_accuracy 0.680 precision 0.255 recall 0.674 f1 0.370 confusion matrix: [[ 21657 9878] [ 1635 3375]] label: power balanced_accuracy 0.701 precision 0.346 recall 0.699 f1 0.462 confusion matrix: [[ 20996 8857] [ 2016 4676]] label: thrash balanced_accuracy 0.608 precision 0.229 recall 0.594 f1 0.331 confusion matrix: [[ 19106 11626] [ 2359 3454]] Average binary classification scores: balanced_accuracy 0.67 +/- 0.07 precision 0.33 +/- 0.18 recall 0.66 +/- 0.08 f1 0.43 +/- 0.16 Multi-label classification metrics: accuracy 0.32 precision 0.35 recall 0.67 f1 0.46 hamming loss 1.66 ROC AUC scores: black : 0.772 death : 0.695 heavy : 0.749 power : 0.772 thrash : 0.655 macro-avg : 0.729 +/- 0.046
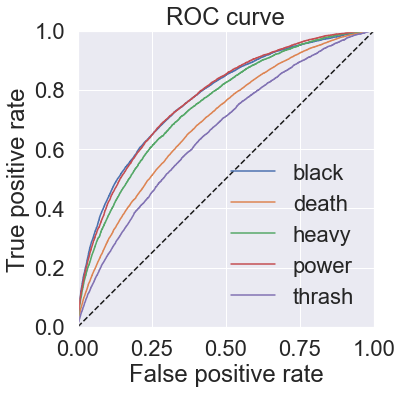
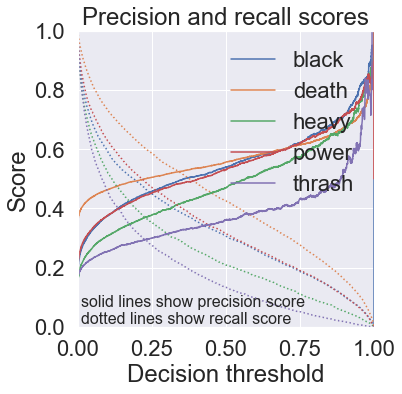
Show code
print("Thresholds:", keras_mlc.threshold)
keras_pipeline.fit(X, y, labels=genres, verbose=0)
keras_pipeline.set_threshold(keras_mlc.threshold)
for text in test_corpus:
print(text)
keras_pipeline.classify_text(text)
print()Thresholds: [0.04349495 0.17454619 0.03878406 0.06144459 0.04794146] C:\Users\philn\AppData\Roaming\Python\Python39\site-packages\sklearn\utils\deprecation.py:87: FutureWarning: Function get_feature_names is deprecated; get_feature_names is deprecated in 1.0 and will be removed in 1.2. Please use get_feature_names_out instead. warnings.warn(msg, category=FutureWarning) 100%|████████████████████████████████████████████████████████████████████████████| 32889/32889 [10:27<00:00, 52.44it/s] Classification: THRASH, HEAVY, POWER Individual label probabilities: thrash 22% heavy 18% death 15% power 14% black 1% satan Classification: BLACK Individual label probabilities: black 100% thrash 1% heavy 0% death 0% power 0% flesh Classification: BLACK Individual label probabilities: black 100% death 1% thrash 0% power 0% heavy 0% fight Classification: NONE Individual label probabilities: black 0% death 0% thrash 0% heavy 0% power 0% attack Classification: NONE Individual label probabilities: power 1% black 0% heavy 0% thrash 0% death 0%